The Quick Rundown:
ZeroMatter is leveraging simulation to accelerate how robotics and autonomy is built, tested, and trained.
Founded by Ian Glow, who helped pioneer Tesla’s simulation team, ZeroMatter’s team includes engineers who worked on simulation engines at companies like Nvidia, Tesla, and Cruise.
They’re actively hiring for 10 roles, including ML engineers, 3D integration artists, and technical product managers.
This is “Startups to Join” – a blog for engineers and designers to discover early-stage startups that are reimagining industries and on the path to becoming enduring companies. Whether you’re looking for the next unicorn to join or just curious about what VCs are investing in, subscribe below to keep updated.
The Challenge of Robotics
Robots have excelled at mechanically challenging tasks for decades. From the Unimate robot welding car bodies with precision in 1961 to Kiva robots revolutionizing warehouse logistics by autonomously moving shelves, robots have automated the creation and delivery of products we interact with every day. Yet, despite all this progress, robotics is still waiting for its “GPT moment”.
We’ve seen exciting demos year after year: Boston Dynamics’ Atlas can sprint, jump, and backflip; Google’s Everyday Robots can sort trash and open doors; and Tesla’s Optimus promises to cook and fold laundry. But, despite those advancements, we still don’t have a truly general-purpose robot – one that can be deployed into any unstructured environment (like a kitchen) and perform basic tasks (like picking up coffee mugs) without retraining, hard-coding, or constant supervision.
To understand why, it’s important to peel back a layer and get a high-level overview of what it actually takes to develop a robot. While picking up a coffee mug might seem trivial to us, it requires a robot to solve several complex problems in real-time, from perception to kinematics and dynamics.
Problem 1: Perception at Scale
Before a robot can act, it must perceive. This means taking noisy, high-dimensional sensor data, typically from cameras, LiDAR, or depth sensors, and translating it into a broad understanding of the world.
This is a big computational challenge. Consider a robot scanning a desk for a coffee mug. A single RGB image might contain over 2 million pixel values. A depth map could add another 300,000 points. And that’s just in a single 2D snapshot. In our world, robots need to operate in real-time and in 3D environments. This means that their data must update ~30 times per second.
Robots also have to consider structure: if there are 10 objects in a scene and each has 6 degrees of freedom (3 positions, 3 orientations), a robot must reason over a 60-dimensional space. That means considering over 2⁶⁰ (more than a quintillion) possible configurations.
This is known as the curse of dimensionality: as the number of variables increases, the space of possible interpretations grows exponentially. Because of this, even simple scenes like a basic kitchen are a big combinatorial challenge.
Problem 2: Kinematics
Once a robot identifies a mug’s location, it meets its next challenge: figuring out how to move its arm to reach it. This problem is geometric and involves two types of calculations:
Forward Kinematics: “Where is my hand?”
Given all the joint angles of a robot’s arm (shoulder at 30°, elbow at 45°, wrist at 90°), where does the robot's hand end up in 3D space? This is relatively straightforward and involves a series of matrix transformations that combine joint angles into a final hand position. In other words, you’re computing a one-way function: x = f(q), where q is the set of joint angles and x is the position.
Inverse Kinematics: “How do I move my hand there?”
Now, reverse the question: given a target position (x, y, z), what should the joint angles be to place the hand there? This is a much more challenging problem to solve. There may be multiple solutions, no solutions, or configurations that overstretch the robot’s joints. Solving this often requires iterative optimization, numerical solvers, or learning-based ML models (like MLPs).
This complexity explains why robots sometimes pause and think before reaching for objects. And this problem can become even more challenging because of something called kinematic singularities. These are points where small changes in the target location can lead to massive, unstable changes in joint angles. When a robot nears these regions, it may pause, move jerkily, or fail to complete its task.
Problem 3: Dynamics
Once the robot knows where to move its joints, it faces an entirely different mathematical challenge: how to actually move them. This is a dynamics problem. Unlike kinematics (which deals with positions and angles), dynamics involves mass, inertia, torque, and external forces like gravity and friction. The robot’s controller must solve its equation of motion in real-time:

This equation outputs the torque, which represents the twisting force each motor needs to apply to move smoothly. It depends on several factors, including:
An inertia matrix, representing how mass is distributed across a robot’s joints
Coriolis and centrifugal forces, representing the forces resulting from the arm’s motion itself
The gravitational load, which gets stronger as the arm extends horizontally
Frictional forces (vary with speed and wear)
For our coffee mug example, when the robot extends its arm toward the mug, gravity exerts more torque on the shoulder joint than when the arm is tucked close to the body. The controller must calculate exactly how much extra torque each motor needs to counteract this gravitational load while maintaining smooth movement. If it undercalculates, the arm will miss the mug. If it overcalculates, the arm will overshoot.
Together, these challenges (multidimensional perception, kinematics, and dynamics) compound; each problem is interdependent. The robot must solve all of them simultaneously and in real-time.
Struggling to Generalize (1961-2010)
The reasons above are just a glimpse into why robotics is so hard. It also helps establish the context for why a lot of progress (until recently) focused on building domain-specific robots in highly controlled environments.
For a long time, most engineers attempted to overcome the challenges we discussed by using a brute-force strategy: explicit object models, deterministic control rules, and finely tuned motion planners. The standard pipeline was linear and modular; perception fed into kinematics, which fed into dynamics, which drove control.
These systems have performed well in tightly controlled environments. On automotive assembly lines, Fanuc robotic arms dominate, completing tasks like spot welding and part insertion. In electronics, Yamaha SCARA robots place electrical components in exact configurations, thousands of times per hour. These systems aren’t only successful in factories either. In hospitals, CyberKnife systems perform targeted radiation therapy by locking onto body frames and pre-mapped coordinates.
These deployments have been so effective because the environments are structured: objects are fixed, lighting is controlled, and every variable can be predetermined. But, the reason we still don’t have general-purpose robots is that outside these controlled domains, the hand-crafted pipeline approach breaks down. Why? Because environments change constantly and this approach doesn’t enable robots to learn and adapt. If we go back to our mug example, when a mug handle breaks, our robot might no longer recognize the object or know how to pick it up unless it’s been preprogrammed to handle that situation.
This gap between structured success and unstructured failure is known as Moravec’s Paradox: “what is hard for humans is easy for machines, and what is easy for humans is hard for machines”. The paradox arises because our sensorimotor capabilities are the product of a lot of years of evolution, whereas abstract reasoning is a relatively recent development. So while a robot can solve a high-dimensional optimization problem in milliseconds, it might still struggle to recognize a partially hidden coffee mug or adjust its grip when the mug is slippery.
Learning-Based Robotics
As the 2010s came around, research on general-purpose robotics in unstructured environments was approaching a ceiling. While industrial robotics continued to thrive in controlled manufacturing settings, robots struggled to operate reliably outside carefully engineered scenarios. Product demos continued to get better, but practical applications requiring adaptability remained limited.
But, as robotics was going through a trough of disillusionment, the research that would eventually power both the LLM revolution and a new era of learning-based robotics was beginning to emerge.
The Perception Revolution
In 2012, AlexNet achieved a breakthrough on the ImageNet Large Scale Visual Recognition Challenge, reducing the top-5 error rate from 26.2% (2nd place) to 15.3%. Unlike traditional computer vision models, AlexNet used convolutional neural networks (CNNs) trained on large datasets that learned rich visual representations. While AlexNet did require significant architectural design choices, data augmentation strategies, and preprocessing decisions, it ultimately showed that end-to-end learning could discover visual representations more effectively than hand-crafted feature engineering.
The implications for robotics were obvious: what if, instead of writing rules for perception, we trained robots to see using learned models?
This idea immediately gained adoption within the robotics perception stack:
Object Detection: CNN-based models like R-CNN (2014) and Fast R-CNN (2015) began outperforming traditional vision pipelines in robotic object detection tasks, handling occlusion and viewpoint variation more robustly.
Grasp Prediction: Researchers developed deep models for RGB-D-based robotic grasping, using CNNs to predict grasp opportunities directly from camera images rather than relying on geometric models of objects.
Pose Estimation: DeepPose (2014) and PoseNet (2015) used deep networks for 6DOF pose estimation, gradually eroding the dominance of geometric SLAM and localization methods.
This marked a shift in the way robots were built: robots could now see the world using perception systems trained on large datasets instead of pre-defined rules.
The Control Revolution
Parallel to the perception revolution, breakthroughs in reinforcement learning (RL) began changing how robots learned to act. Traditional control systems for robots relied on carefully tuned PID controllers, trajectory optimization, or finite state machines programmed by experts. RL offered a different approach: an approach where agents learn to act by maximizing reward through trial and error. In RL, an agent (the robot) learns to act by interacting with its environment, receiving rewards for good outcomes, and penalties for bad ones. Over time, the robot learns a policy: a mapping from observations (e.g., camera input, joint positions) to actions (e.g., motor torques or gripper commands) that maximizes its cumulative reward.
In other terms, RL solves a Markov Decision Process:
State: The current configuration (e.g., mug location, arm configuration)
Action: The decision the robot makes (move left, close gripper)
Reward: A scalar signal (+1 for successful grasp, -1 for failure)
Policy: A function that maps states to actions
RL is especially useful in robotics because many tasks don’t have explicit ground truth labels (as in supervised learning) but can instead be framed in terms of success or failure. For instance, if a robot is learning to open a drawer, success could simply be defined as the drawer being open at the end of a training episode.
While RL in robotics dates back to the 1990s, the core breakthrough that shaped modern robotics came with deep reinforcement learning. DeepMind's Deep Q-Networks (DQN), published in 2015, demonstrated that neural networks could learn complex policies directly from high-dimensional observations like raw pixels. Though applied to Atari games rather than robotics, DQN sparked research into end-to-end learning from experience.
Guided Policy Search: At UC Berkeley, Pieter Abbeel and Sergey Levine developed Guided Policy Search, which combined trajectory optimization with supervised policy learning. Their research showed a PR2 robot learning to insert a peg into a hole using only raw camera input.
Algorithmic Advances: TRPO (2015), DDPG (2016), and PPO (2017) provided more stable and sample-efficient RL algorithms, while frameworks like OpenAI Gym and physics simulators like MuJoCo democratized experimentation.
Continuous Control: Unlike discrete Atari actions, robotics requires continuous control in high-dimensional action spaces, which ultimately led to the development of domain-specific approaches like actor-critic methods and policy gradient algorithms.
Yet, despite all the great things about RL, it was also sample-inefficient. Training a robot to open a drawer or pick up a mug requires thousands of attempts, taking days of robot time, and reward signals could be hard to define. This limitation partially led to the creation of a more sample-efficient approach: imitation learning. Instead of learning from scratch via rewards, in imitation learning, the robot is shown expert demonstrations (typically from a human) and uses supervised learning to train a policy that mimics the expert. By using methods like DAgger to mitigate the effect of small errors compounding, imitation learning has proven to be an effective training approach for modern robots, especially for tasks like robotic manipulation.
Ultimately, these new research breakthroughs – RL and imitation learning – presented compelling evidence that learning from interaction (via a reward or imitating an actual demonstration) could be a better path toward building general-purpose robots than the brute-force solutions of the past.
The Data Scaling Hypothesis
As research around imitation learning and RL grew, one insight became clear: if robots learn from data, better robots will require more data. This was validated empirically by Google's study that used 800,000 real-world grasp attempts to train a CNN to predict grasp success from visual input. The key finding was that success scaled directly with the amount of interaction data, ultimately foreshadowing the scaling laws that we’re very familiar with in LLMs today.
Building on these results, researchers started hypothesizing: rather than training a separate policy for each goal, could a single model learn to generalize across tasks if trained on enough diverse data?
Sound familiar? Soon enough, the research breakthroughs in LLMs began to influence robotics. While robotic models aren’t trained with tokenized text or causal decoding, they do benefit from the same ability to model sequential dependencies and long-range context. Specifically, the transformer architecture offered a promising foundation on the path to a general-purpose robot. Within a few years, the architecture has already produced some key breakthroughs:
RT-1 (2022): In 2022, Google Robotics introduced RT-1, a transformer trained on over 130,000 real-world episodes of robot interaction, covering 700+ tasks in home and kitchen environments. The system treated robot control as sequence modeling, processing sequences of [image₁, action₁, image₂, action₂, ...] to learn complex behaviors. Rather than using explicit task labels, the model learned to map language instructions and image sequences to low-level actions. The diversity of the data used was key: multiple robots, settings, and object types.
RT-2 (2023): Building on RT-1, RT-2 incorporated pre-trained vision-language models, enabling zero-shot generalization to unseen instructions and objects. This integration of web-scale vision-language pretraining with robotics data represented a big step forward.
PaLM-E (2023): A 562-billion parameter multimodal transformer that combined Google's PaLM language model with robotic sensor inputs. PaLM-E could plan and reason across modalities, answer questions like “Where is the sponge?”, and control robots using language-conditioned policies.
Integration Architectures: Systems like SayCan, RoboCLIP, and PerAct demonstrated how large vision-language models could be integrated with low-level robot control, enabling goal-driven behavior from open-ended natural language instructions.
Together, these models showed that scale and diversity of data, not just architectural advances, are critical for building general-purpose robotic systems. That’s why so many people are incredibly excited about the future of robotics over the next few years. It finally feels like we are actually near a general-purpose robot. Just this week, Sam Altman wrote this:

The Data Race
But, unlike LLMs, a general-purpose robot isn’t here yet. While some argue that we already have the learning algorithms to build these robots, one thing is clear: we are missing a key ingredient – data.
The data to build a general-purpose humanoid robot is very different from the data needed to build an LLM. LLMs succeeded because they could train on trillions of tokens on the internet. Robotics lacks this luxury entirely. Instead of AMA threads on Reddit, robots need hundreds of hours of annotated video showing precise forces, torques, and contact points; kinesthetic data capturing pressure and object response; and environmental context including lighting and surface properties. This data is expensive, time-consuming to collect, and often hardware-specific. A single hour of high-quality robot training data might cost thousands of dollars to generate and annotate, compared to essentially free text data scraped from the web.
Because of this, the amount of data we still need in order to train a general-purpose robot is significant. While GPT-3 was trained on roughly 45 terabytes of text, the largest robotics datasets available contain around 1 million trajectories (a deficit of 4-6 orders of magnitude). This data constraint also explains why robotics progress has been so uneven. Companies with access to large-scale data collection (e.g., Tesla and Waymo via Google) have been able to achieve breakthroughs impossible for smaller teams.
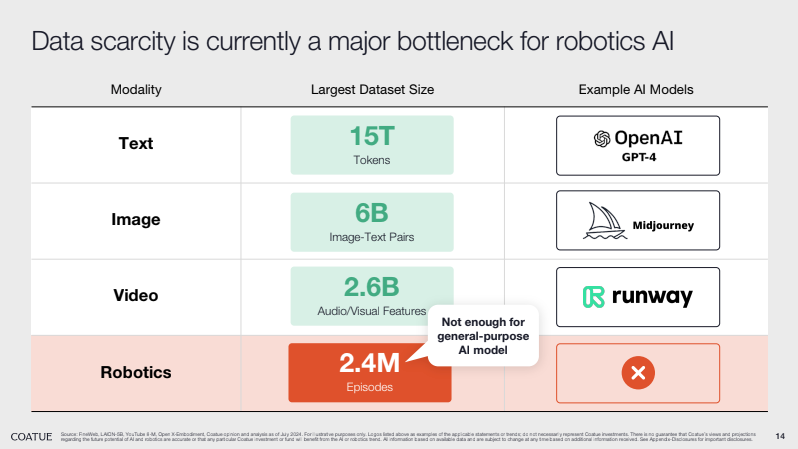
Right now, the main approaches to gathering enough data to train robots are as follows:
Teleoperation (demonstration data): a human controls the robot to complete tasks (like flipping pancakes), creating clean, labeled data as a result. There’s some cool startups working here to reduce the cost of teleoperation (including a YC-backed company called Sensei).
Open-source sharing: datasets like DROID pool data from universities and labs to reduce duplication of effort.
Learning from video: Robots watch video demonstrations (e.g., from YouTube or AR devices) and try to extract meaningful patterns.
Simulation: Instead of relying on data collected in the real world, this approach simulates the real world and trains robots entirely in these virtual worlds.
While each approach has its own unique opportunities, I’d argue that simulations are the most interesting and (probably) the most cost-efficient solution. Teleoperation data requires access to lots of human labor and expensive hardware. Learning from videos is an ambitious task – even if robots can learn without annotated motor control data, there aren’t enough videos of humans folding laundry to sufficiently train a robot to be effective. And while open-source datasets are promising, they are still very far away from the scale of data needed for a general-purpose robot.
Jensen Huang recently commented on these exact challenges:

I think simulation will be the “clever way” to produce millions of synthetically generated motions that Jensen refers to. As Jim Fan of Nvidia puts it:
“In simulation, you can have all the actions, and you can also observe the consequences of the actions in that particular environment. And the strength of simulation is that it’s basically infinite data. And, you know, the data scales with compute—the more GPUs you put into the simulation pipeline, the more data that you will get.
And also the data is super real time. So if you collect data only on the real robot, then you are limited by 24 hours per day. But in simulation, like the GPU-accelerated simulators, we can actually accelerate real time by 10,000X. So we can collect the data at much higher throughput given the same amount of time. So that’s the strength”
That isn’t to say that simulation doesn’t have its own challenges. Modeling the physics of the real world is incredibly difficult, and policies trained in simulation often fail when deployed on robots in the real world (aka the sim-to-real gap). But these problems are solvable. For instance, while the sim-to-real gap is still a challenge, successful approaches to counteract this have already been developed.
One early approach is domain randomization: a method that systematically varies simulation parameters (gravity, friction, weight, etc.) during training to teach policies how to deal with changes in environments. In practice, this looks like running 10,000 different simulations in parallel, but with each simulation essentially being its own world with slightly different parameters. This approach is being used with great success – Nvidia recently demoed humanoid robots that “went through 10 years of training in only 2 hours of simulation time” to learn how to walk. These robots were trained exclusively in their simulation software, Isaac Sim, and the whole training required a neural net with just 1.5 million parameters. By using domain randomization, they were able to transfer that learning zero-shot without any fine-tuning to real-world robots.
All of this is why leading researchers like Dr. Fei-Fei Li have said that “simulation is very underrated” and why Nvidia is “using simulation heavily in [their] approach to build robotics”. It’s also my long-winded way of explaining why I’m covering ZeroMatter – a startup leveraging simulation to accelerate how robotics and autonomy is built, tested, and trained – for this edition of Startups to Join!
ZeroMatter
Founded by Ian Glow, who helped pioneer Tesla’s simulation team, ZeroMatter is building what they describe as "one platform to build, test, and train anything" – a unified simulation environment built to solve robotics' data problem. They aren’t just focusing on humanoid robots; they also view autonomous vehicles, drones, and aerospace as some of the potential applications. Below is a brief overview of some of the features they are building:
Sensor Simulation: ZeroMatter emphasizes fidelity in modeling the sensors that autonomous systems use – cameras, LiDARs, radars, ultrasonics, etc. The goal is to produce virtual sensor data that is indistinguishable from reality (not just to the human eye, but to machine perception algorithms). This involves photorealistic rendering techniques and physics-based sensor models that result in virtual worlds that look and behave like the real world under various lighting, weather, and physics conditions. Materials in the scene are modeled with physical accuracy across the electromagnetic spectrum, meaning a surface will reflect infrared or LiDAR pulses just as a real material would. This is crucial for training perception AI.
Automatic Environment Generation: To train and test autonomy at scale, you need lots of diverse environments, from city streets to rural backroads, and you must include random variations and edge-case scenarios. ZeroMatter enables automatic environment generation to create hyper-realistic worlds on demand. While not a lot of information is publicly available, their job postings mention using tools like Houdini to algorithmically generate rich virtual environments. This means instead of hand-modeling every street or building, the platform can automatically produce countless realistic maps and scenes, complete with traffic patterns, pedestrians, weather changes, and so on. This dramatically speeds up scenario creation, which is critical in solving the sim-to-reality gap.
Multi-Agent Framework: Modern autonomous scenarios often involve multiple actors (e.g, many vehicles on the road, swarms of drones, or teams of robots). ZeroMatter’s platform is being built to handle multi-agent simulations, meaning many entities can operate simultaneously in the virtual environment. This living world simulation is essential for testing collaborative autonomy and emergent behavior. The multi-agent aspect also extends to reinforcement learning training, where multiple agents can learn concurrently in the same simulation environment.
Integration and Tooling: ZeroMatter is not just a raw simulator. Instead, it comes with development tools including APIs/SDKs to integrate autonomous system software into the simulator (for software-in-the-loop testing), tools for configuring scenarios and setting test parameters, and dashboards for monitoring simulations. It also likely supports sensor injection for teams to combine real-world logs with simulation data.
Overall, ZeroMatter is building an end-to-end simulation engine that should enable robotics teams to sign up, import their robot model, set up some scenarios (or let the system generate them), and immediately start testing and training. And while a lot about their product is still not publicly available, the talent density at ZeroMatter is extremely high. With engineers who worked on simulation engines at Tesla, Cruise, Nvidia, and FAANG, “this isn’t their first simulated rodeo” :)
Concluding Thoughts
If being part of the “GPT moment for robotics” sounds exciting to you, ZeroMatter is hiring across lots of roles, from ML engineers to product managers and technical artists. Check out their jobs page here or send over an email to careers@zeromatter.com.
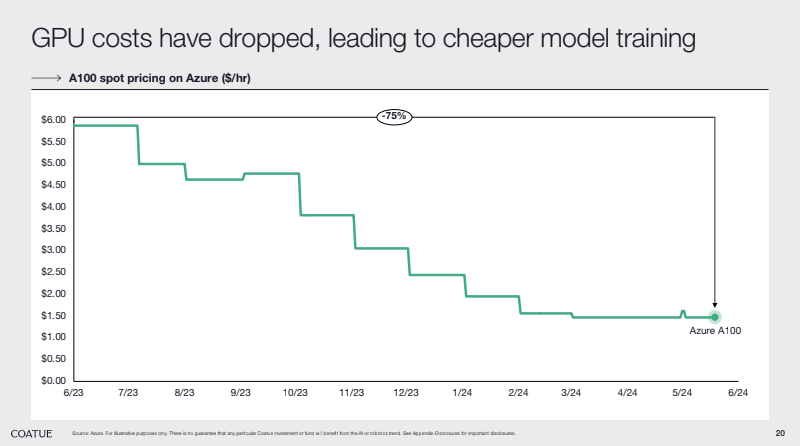
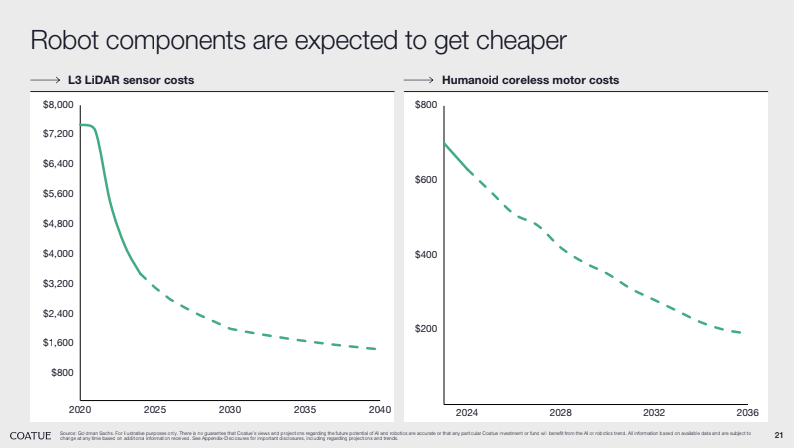
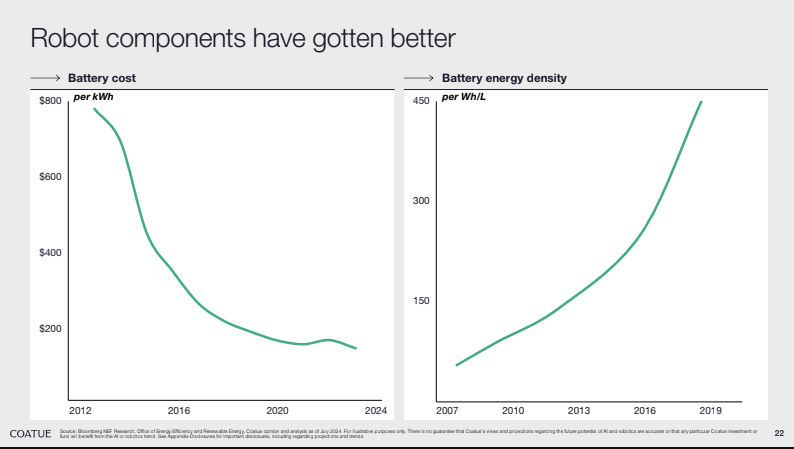
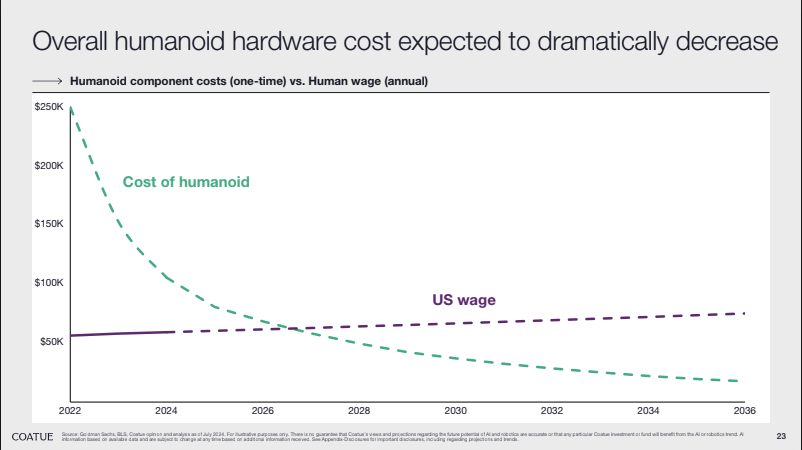
Side note: this deep dive didn’t touch on the other big tailwind in the space: reducing hardware costs. There’s enough content on that for another article, but Coatue’s slides (see below) do a great job of showcasing some of the high-level trends: