
Startups to Join: Physical Intelligence
Bringing general-purpose AI into the physical world

The Quick Rundown:
Physical Intelligence is developing a foundation model to solve the lack of intelligence in robotics (with a particular focus on dexterous manipulation at present).
Founded by researchers who have contributed toward defining robotics learning algorithms and approaches, they’ve already released models with strong generalization performance.
They’ve raised $475M from Bond, Jeff Bezos, Khosla Ventures, Lux Capital, OpenAI, Redpoint Ventures, Sequoia Capital, and Thrive Capital.
They’re actively hiring for 10 roles, including ML engineers, research scientists, robot operators, and interns!
This is “Startups to Join” – a blog for engineers and designers to discover early-stage startups that are reimagining industries and on the path to becoming enduring companies. Whether you’re looking for the next unicorn to join or just curious about what VCs are investing in, subscribe below to keep updated.
Building the ‘GPT of Robotics’
In the last edition of Startups to Join, I wrote about the data bottleneck in robotics and why we may be approaching a ‘GPT moment’ for embodied intelligence. The core idea was simple: recent breakthroughs in learning-based approaches have presented compelling evidence that a scalable path to general-purpose robotic intelligence might be within reach.
The keyword in that sentence is might. As of today, there is still considerable debate about the scale of data required and whether the brain (software) can truly be separated from the body (hardware).
Yet, regardless of where you fall in that debate, one thing is undeniable – robotics has entered a new frontier. In the last few years, we’ve started to move beyond narrow, brute-force systems to models that demonstrate early signs of one-shot generalization in unseen environments, reasoning through multi-step problems, and transferring across robot embodiments. As a result, we now have robots that can achieve the following:
Most of the breakthroughs we see today can be traced back to Google DeepMind. With RT-1, RT-2, and RT-X, DeepMind researchers helped establish the idea that internet-scale data, cross-embodiment training, and semantic grounding can enable general-purpose capabilities. Given this, when 8 of those researchers at DeepMind leave to start a new company and release a foundation model that powers robots like the one in the video above, it’s worth diving into.
This is exactly why I’m covering Physical Intelligence for this edition of Startups to Join. At its core, Physical Intelligence is a research lab focused on bringing general-purpose AI into the physical world via an embodiment-agnostic foundation model. Unlike most companies that tightly couple their software and hardware, Physical Intelligence is making a different bet – that true generalization will only emerge by training across a wide range of robot embodiments. That bet is already yielding promising results: their latest model achieves ~80% task success in unseen home environments, with only 2.4 % of the training set coming from mobile‑manipulator-in‑home data. Though early, that’s already a notable signal that a generalized model may not only be feasible, but also achievable from a data perspective.
The Foundational Building Blocks
Before we unpack how Physical Intelligence’s model works or why they believe in an embodiment-agnostic approach, it’s worth rewinding to understand the evolution of learning-based robotics.
First, in 2022, researchers at Google DeepMind (including Chelsea Finn, Karol Hausman, Brian Ichter, Sergey Levine, Karl Pertsch, and Quan Vuong, among others) published a paper on RT-1 – a transformer-based model that treated robot control as a sequence modeling problem. Before RT-1, most models in robotics relied on hand-engineered pipelines where each component (like object detection or motion planning) had to be designed and tuned separately. RT-1 changed this architectural approach by unifying these separated systems into a single, end-to-end neural model that learned to map directly from input to output.
The inputs to RT-1 are twofold: images from the robot’s cameras (its view of the world) and a natural language command like “pick up the rice chips”. These inputs are fed into a transformer-based architecture that combines the visual and language data into a single representation. The output of the model is a robot's low-level control commands. These are the precise movement instructions that can be executed immediately.
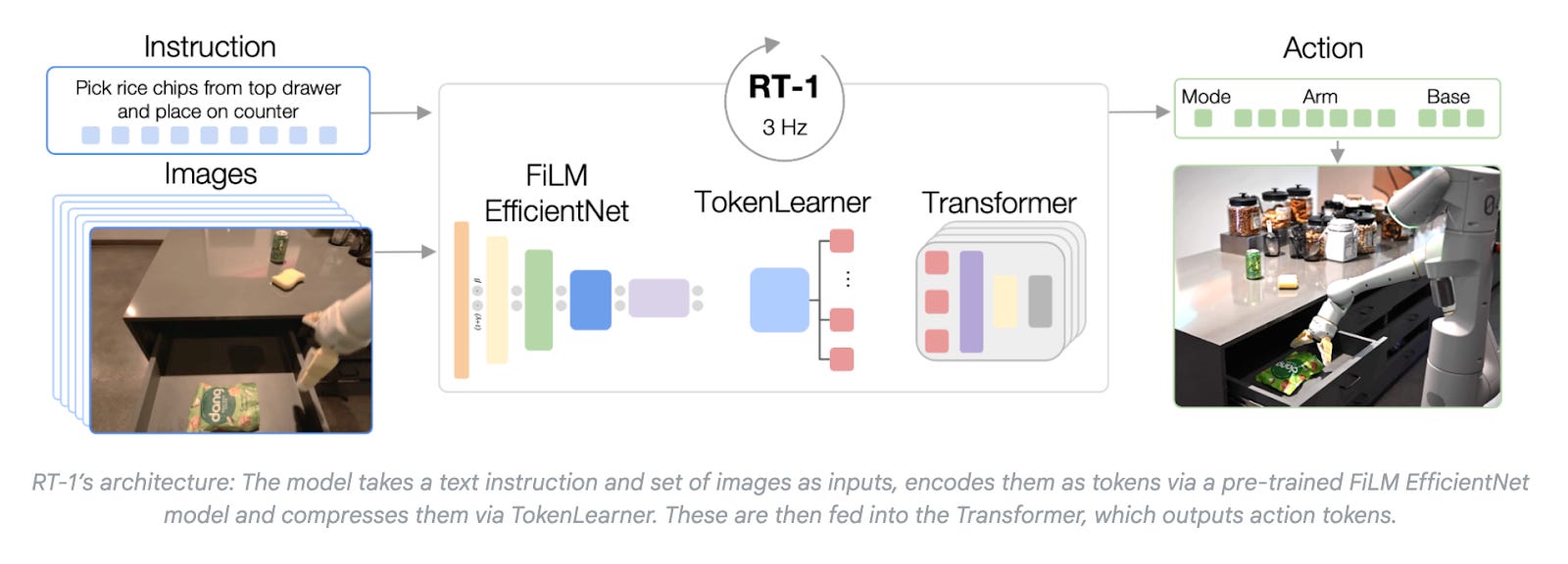
To build RT-1, the model was trained on 130,000 robot demonstrations using identical robot arms in a controlled lab setting. The dataset contained 700+ tasks, from simple rearrangement to object placement. In terms of performance, the paper reported the following:
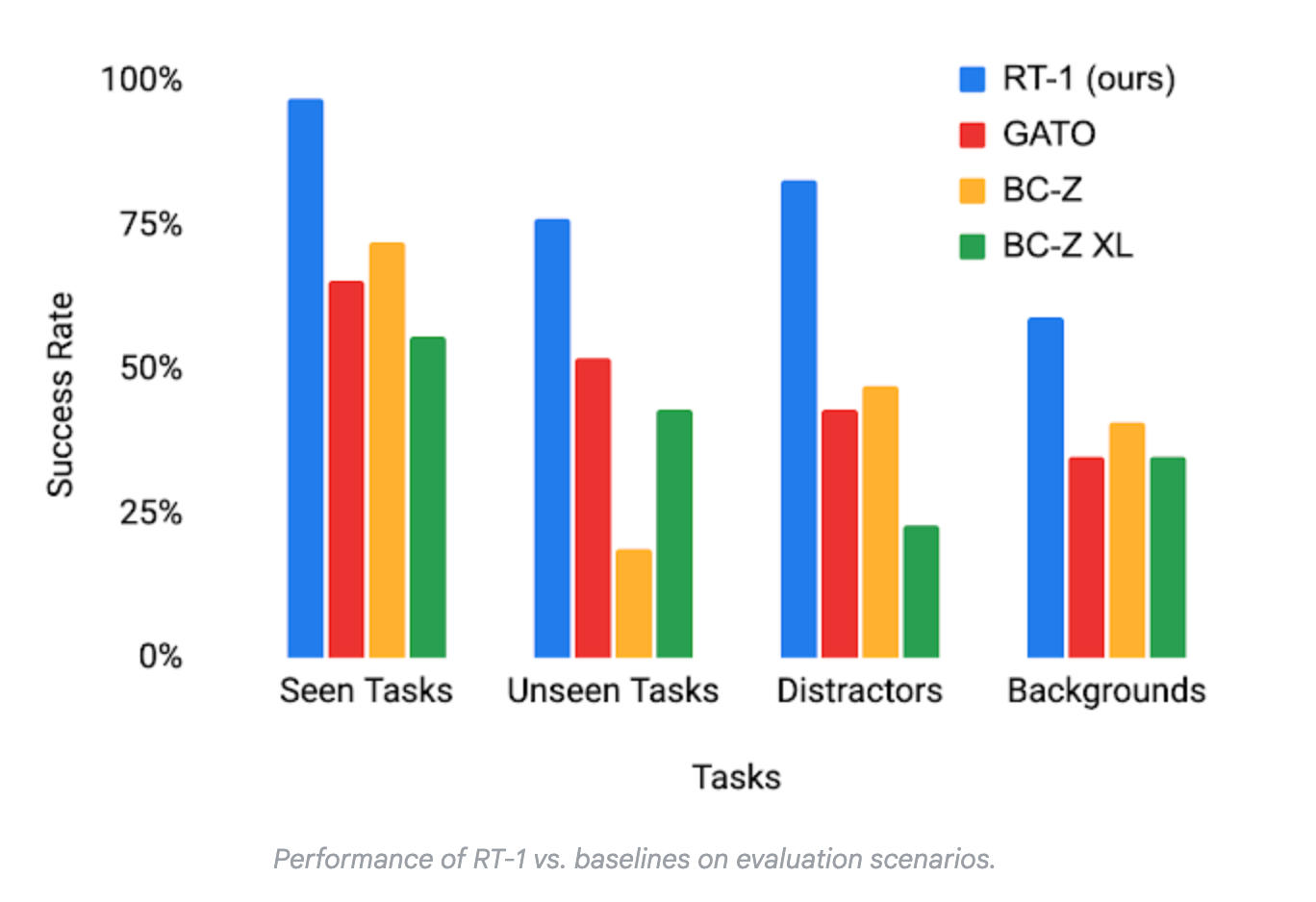
Yet, while those numbers were strong on the surface, there were many key limitations.
First, although its in-distribution performance is great, you can’t train a model on every single possible command. Out-of-distribution performance really matters, and the model wasn’t built for open-ended generalization (e.g., interpreting commands like “move the trash” or reasoning over multiple steps). This meant it couldn't “generalize to a completely new motion that has not been seen before”.
Second, RT-1 used an imitation learning method trained on teleoperation data, without any large-scale pretraining on semantic data. Given this, it lacked a deep understanding of object concepts and task semantics. So while it could follow surface-level instructions like “move a red cup”, it had no concept of what a cup actually was. This meant it often failed when dealing with new contexts or instructions requiring human-like reasoning. For instance, the command “move the trash” requires understanding what counts as trash, where trash is likely to be located, and what a trash can looks like. Those are all contextual clues that can’t be inferred from task demonstrations alone.
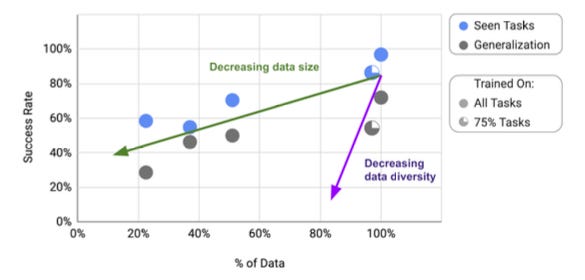
Third, while the amount of data collected was impressive, it wasn’t a scalable approach – the 130,000 demos required 13 robots running over 17 months in a lab. Alongside the time and resource costs, RT-1’s performance only scaled with task-specific data: introducing new objects or environments often required dozens (and sometimes hundreds) of new demonstrations. This made RT-1’s architecture expensive to adapt and not purpose-built for cross-environment transfer or out-of-distribution tasks.
Therefore, although RT-1 proved that an end-to-end transformer could successfully map vision and language commands to robot actions, it simply wasn’t sufficient for real-world deployment across open-ended tasks. It did, however, provide the basis of some foundational concepts, such as that “data diversity has a higher impact on performance and generalization than data quantity”.
Understanding the World
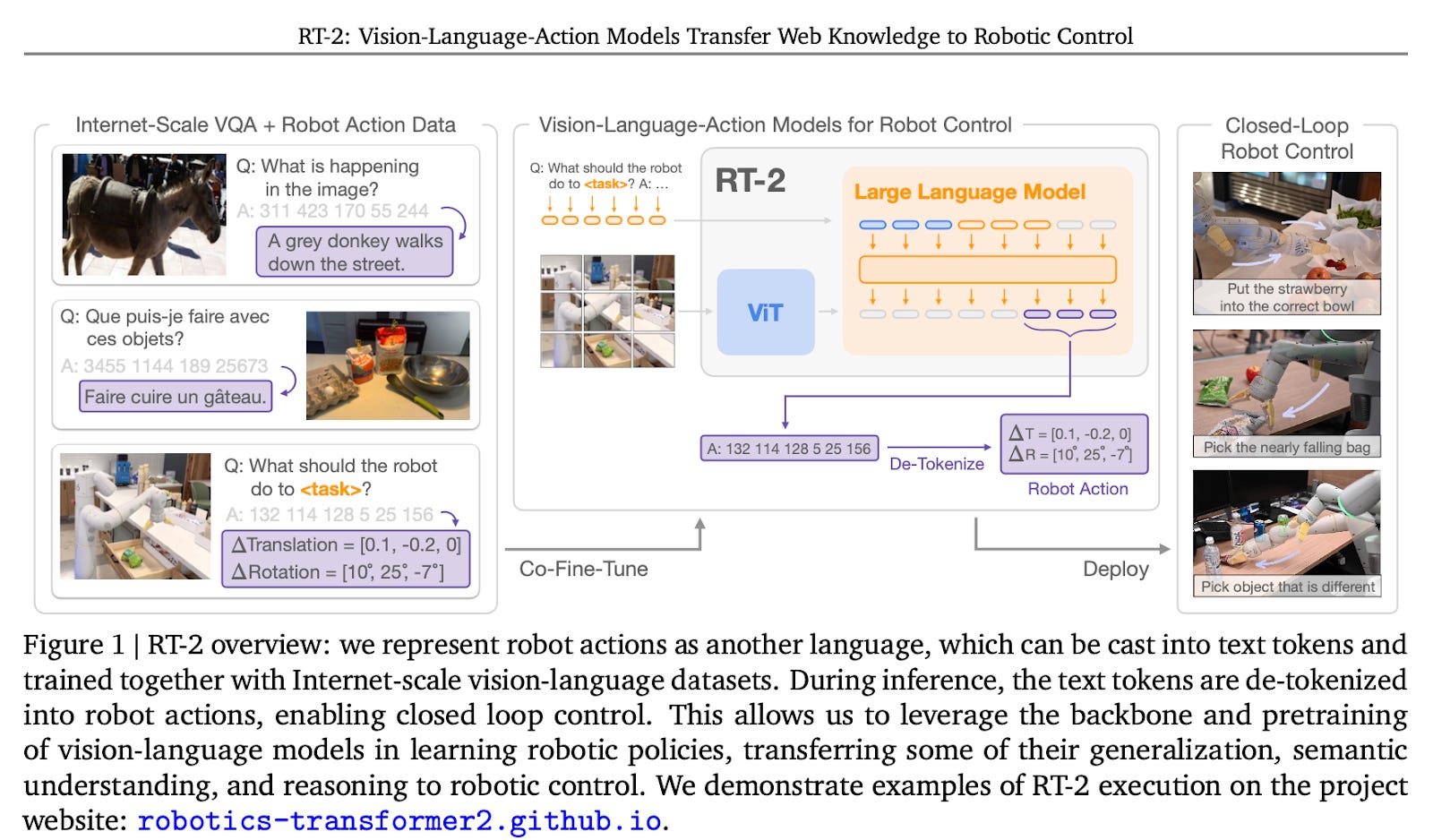
In 2023, DeepMind built on the work of RT-1 by introducing RT-2, a model trained in two stages:
The first step was pre-training. RT-2 leveraged a vision-language model (VLM) that was trained on image-text datasets from the internet. This allowed it to contextualize basic facts about the world, such as knowing that Taylor Swift is a singer, an apple is a fruit, and that trash typically goes in a bin.
The second step involved co-training this pre-trained VLM with robotics data using image-language-action triplets (i.e., visual observations, language commands, and the corresponding robot actions). This process aligned the model's understanding of language and vision with grounded physical tasks. The product of this training was a vision-language-action (VLA) model: a system that could take in images and natural language commands, and output tokenized actions representing robot control instructions.
By using a pre-trained VLM as the basis for the model, RT-2 was able to gain semantic understanding from internet data, enabling it to generalize to scenarios that weren't explicitly present in the training set. On top of gaining this contextual awareness, RT-2 had another important breakthrough:
In RT-1, robot actions were limited to a small set of hand-picked commands (e.g., “move left” or “grip"). RT-2 took a different approach: it treated actions as non-linguistic tokens designed specifically for robot control. Tokens are how LLMs process sequences of text, and RT-2 effectively adapted this idea for physical actions. This design allowed RT-2 to use the same encoder-decoder architecture as vision-language models with minimal changes. As a result, the model could be fine-tuned to predict robot actions much like LLMs predict words, making it easier to adapt pre-trained VLMs for robotics.
Because of this architectural change, RT-2 was able to generalize out-of-distribution and solve simple reasoning tasks that were not explicitly demonstrated during training. In terms of performance, RT-2 achieved around 3x the success rate in similar evaluation setups as RT-1 and especially outperformed in zero-shot settings where the exact command or object configuration was never seen before.
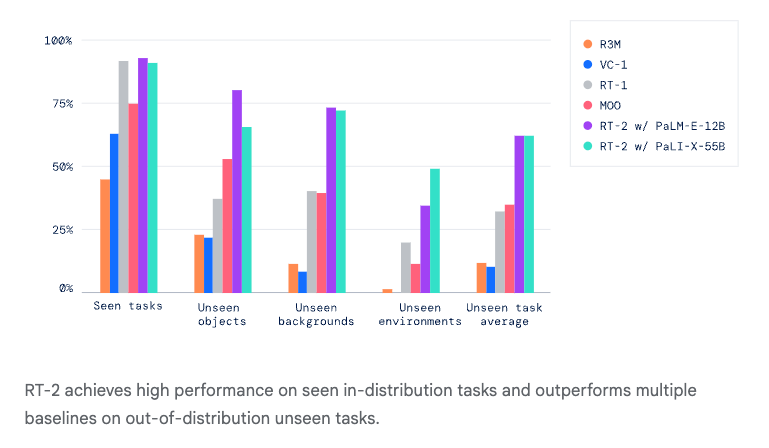
Today, RT-2's architectural approach of integrating VLMs into robotic control remains relevant, even in SOTA models. But, despite its abilities, RT-2 still had one major shortcoming: it was trained and evaluated on a single robot type, using data collected in a single lab environment. That meant the model couldn’t generalize to new robots with different kinematics, sensors, or control schemes without additional retraining or adaptation.
From One to Many
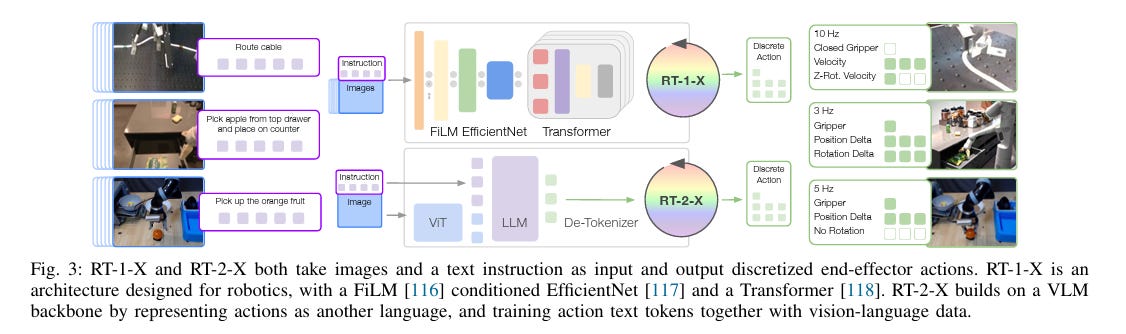
In October 2023, DeepMind addressed the embodiment problem with the release of RT-X, a family of models trained on data from 22 different robot types. This work was made possible because of the Open X-Embodiment dataset, a dataset resulting from 21 institutions collaborating to unify robot demonstrations into a shared format containing 160,266 tasks. The RT-X models (RT-1-X and RT-2-X) were trained end-to-end on this cross-robot dataset using the same architectural designs as RT-1 and RT-2, respectively.
In other words, the models took in visual observations (from sensors and cameras) alongside language commands and outputted sequences of high-level action tokens, which were then translated into robot-specific movements via a low-level controller. To support multiple robot embodiments, the models were trained on a shared action vocabulary that was standardized across robots. Then, a separate embodiment-specific controller translated these intended actions into robot-specific movements.
And it turned out that training a model across multiple embodiments not only leads to better generalization, but also better performance! Given how RT-X was trained, it’s natural to expect the model to generalize better than a task or embodiment-specific model. But what made RT-X so remarkable is that it didn’t just generalize better – it also outperformed models built for specific tasks or embodiments, even when tested solely on those same tasks or embodiments. This is because training across diverse embodiments and tasks gave RT-X a stronger understanding of core patterns, which also improved its performance in narrow settings. As a result, RT-X was the best of both worlds: a model that could adapt to unseen scenarios with strong performance. Put simply, the generalist surpassed the specialist.
In terms of generalization, RT-2-X showed up to a 3x improvement in zero-shot generalization when compared to RT-2. Regarding its performance, RT-1-X had a mean success rate that was 50% higher than specialist models. Findings like these are usually the product of cherry-picked results, but that wasn’t the case with RT-X – third-party researchers evaluated RT-X against their own SOTA models, and it outperformed all of them. To put this in context, these SOTA models were the product of years of research work targeting a specific problem or form factor.
In many ways, RT-X resulted in robotics crossing a new boundary. The architecture didn’t just generalize across tasks; it generalized across embodiments and achieved better performance than specialist models. Today, RT-X's architecture serves as the template for building a universal brain to power robots.
The Strategic Debate
However, not everyone agrees that building a universal brain is the way forward. Some believe that software must be deeply connected to hardware, and that an embodiment-agnostic model will never be sufficient for high-performance deployment. Aaron Saunders, CTO of Boston Dynamics, shares this view. He believes that you can decouple perception and decision-making from hardware when objects are lightweight and inertially irrelevant, but as soon as a task involves lifting heavy objects or interacting with fragile materials, the physics of the robot’s body matters. This view is echoed (more or less) by companies like Figure AI, Tesla, 1X, and Agility Robotics.
The counterargument to this full-stack approach lies in the complexity of manufacturing. Even within a single robot fleet, there is still hardware variability. Small differences in joint calibration, actuation dynamics, or sensor alignment cause differences (and drops) in performance. To solve for this, researchers typically use domain randomization during training (exposing the model to a wide range of simulated variations). But this introduces a tradeoff: generalization improves, while peak precision drops as the model has to hedge across many potential dynamics. This leads to robust control policies at the cost of precision.
But, as discussed in our section on RT-X, this tradeoff may be avoidable. If you can train a universal model across many embodiments (instead of one brain for each), you can potentially get the best of both worlds: precision and generalization. Yet, while software-focused companies can pursue this embodiment-agnostic approach, the calculus doesn’t work for full-stack companies that are in a race to commercialization. The reason why: differing priorities.
Building dexterous hardware is incredibly challenging. Once it’s built, there’s pressure to deploy it immediately and produce impressive demos. This means companies like Tesla are somewhat incentivized to focus on short-term outcomes. Training an embodiment-agnostic system pushes in the opposite direction. It’s just as technically demanding as building dexterous hardware, and despite its long-term potential, current models still fall short of zero-shot cross-embodiment. Combine this with the friction of collecting diverse multi-embodiment data, and the calculus no longer looks enticing (especially when short-term outcomes are the priority).
In some ways, there is an analogy here to how research progressed in AI. Before GPT, most companies built narrow models for specific NLP tasks, like machine translation. But the real breakthroughs came when we flipped the approach: instead of optimizing for a particular use case, researchers built a generalist model first, and the downstream applications followed. In robotics, building a hardware-specific model today is the equivalent of building a task-specific NLP model a decade ago. It produces short-term results, but to achieve long-term physical intelligence, pursuing generalization is likely the way forward.
This is why a research lab that starts with the model, instead of moving backward from a specific problem or embodiment, is more likely to achieve human-level performance. Put differently, research leads and product follows. OpenAI didn’t start with a chatbot and end up with GPT-3.5; they built the model first and then the product around its capabilities. Robotics will likely follow the same trajectory: a research lab will push the frontier, and the hardware will be built around those capabilities. We’ll dive into this point in more depth later on, but it’s worth keeping in mind that this is the key advantage that Physical Intelligence has. By positioning themselves as a research lab, they avoid the immediate pressure to commercialize and can focus on advancing generalization.
In addition to this, there is also the strategic case to be made for the software-focused approach. It is unlikely that any single company owns the entire robot fleet for every task. Just like humans have one brain that can control different types of machines (cars, planes, forklifts, surgical robots, etc.), many believe there will be one robot brain that can be adapted for each embodiment.
As of today, the jury is still out on whether the full-stack or software-focused approach will ultimately win. My intuition is that it seems like there are no bounds to generalization, and cross-embodiment training is one more signal pointing in that direction. As a result, embodiment-agnostic models will outperform hardware-specific ones, similar to how multi-modal models are more capable than language models today.
This is Sergey Levine’s take on the state of cross-embodiment training and how far generalization can go:
“There are still big unanswered questions around cross-embodiment training: How general can such models be? What kind of experience provides positive transfer? Initial evidence is very promising: robotic manipulation policies become better when co-trained on data for robotic navigation, and we can even train policies on data from robots that walk on legs, fly in the air, and manipulate objects with two arms together. But these efforts are still in their infancy – more like GPT-2 than GPT-4 – and we still need plenty of research and realistic, large-scale datasets. However, if we can pool enough data and combine it with Internet-scale pretraining, that might allow us to bootstrap the next phase of robotic learning, where we move toward a robotic data flywheel that allows robots to improve on their own through autonomous deployment. That next phase is where the real power of robotic learning will be realized”.
Based on this high-level framework of software-focused vs full-stack, here is a rough segmentation of companies:

Among software-focused companies, there’s also another important differentiator: generalist vs domain-first.
Domain-first companies build models for a specific task or form factor, allowing for faster deployment. By doing so, they collect large volumes of task-specific data quickly. Some domain-first companies view this as a necessary data-collection strategy on the path to generalized models, while others aren’t focused on generalization at all.
The opposing approach is the generalist one, where companies don’t target a specific domain but instead aim to build a single model that can generalize across tasks and environments (e.g., the “GPT of robotics”). This requires diverse training data from the start and emphasizes foundation model scalability over task-specific performance.
Yet again, the jury is still out on which approach will be the winning one. My intuition here is that breadth matters a lot more than depth – having a handful of real-world demonstrations in each domain is more valuable than having thousands in one domain. After all, generality improves task-specific performance; every task in the world has a long tail of out-of-distribution edge cases, and stronger generalization is more likely to solve for this.
With this new axis in mind, below is an updated segmentation of the key companies:

Overall, while the debate is still far from being decided, I believe one strategy has a clear structural advantage: a research lab pursuing a software-focused, generalist approach. This is because research labs aren’t constrained by short-term deployment cycles, enabling them to explore the bounds of generalization and ultimately pursue long-horizon research questions. The most important of all these research questions is whether an embodied scaling law exists, and if so, on what axis. The first research team to answer that question and that has the resources to act on it will have a critical lead.
With $475 million in funding and a highly talent-dense team, this is the exact advantage that Physical Intelligence has. Remember those researchers I named at the very beginning when introducing Google’s work on RT-1? They are all part of the Physical Intelligence team, working to deploy that research and ultimately build a general, embodiment-agnostic model. They’re also joined by a team who have dedicated their entire careers to robotics, including the likes of Danny Driess and Homer Walke (both of whom contributed to RT-X).
Physical Intelligence
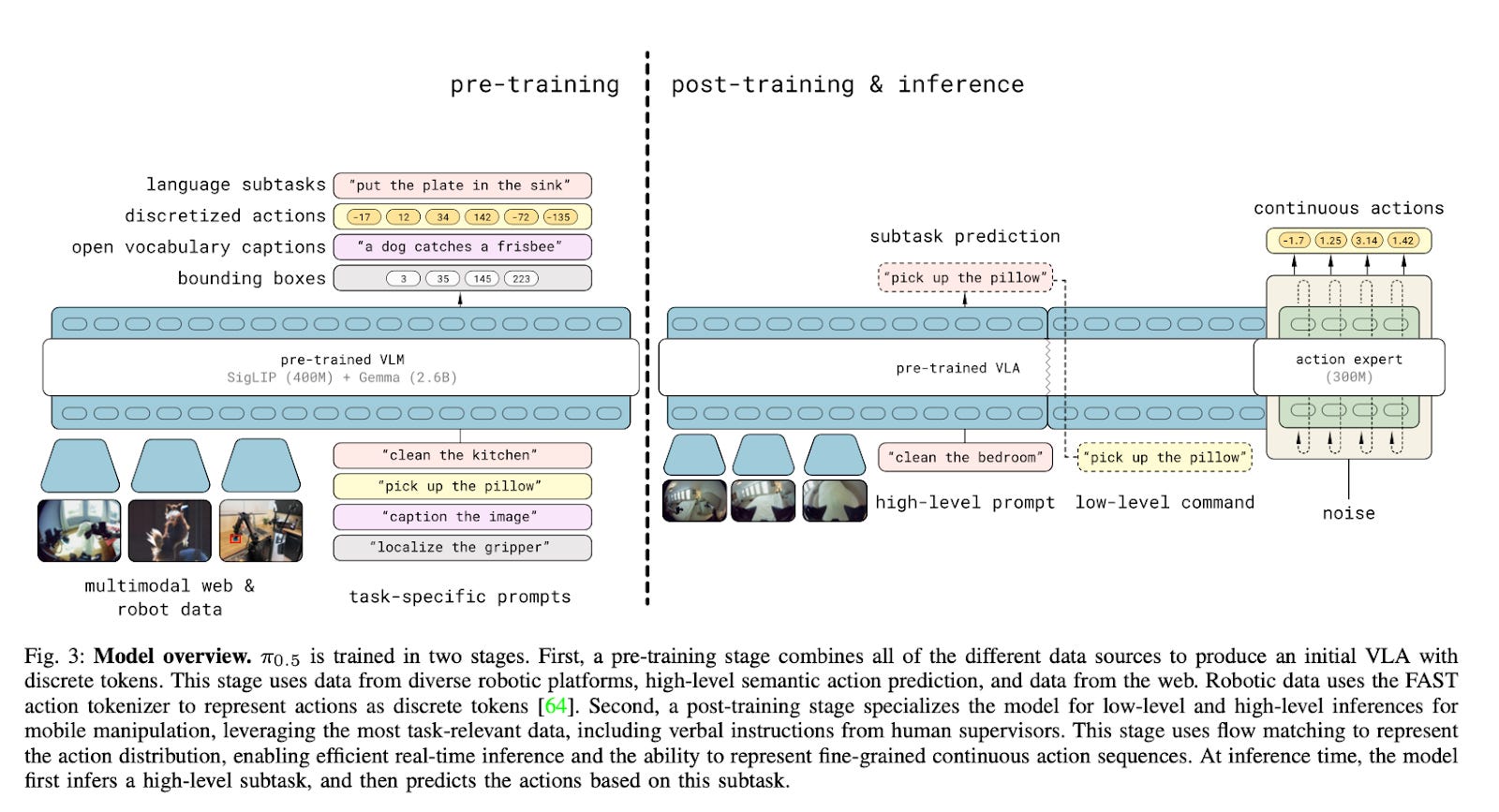
Although the company was founded in 2024, the team at Physical Intelligence has already published work on their generalist policies, π and π0.5.
π0.5, released in April this year, is a VLA model designed to combine high-level reasoning and low-level motor control in a single architecture. It’s trained in two stages:
1) Pre-training to develop general knowledge, semantic understanding, and task decomposition
2) Post-training for mobile manipulation and skill specialization
In the first stage, π0.5 is pretrained on heterogeneous, multi-modal data to help the model learn both how to perform tasks and why certain behaviors are appropriate in a given context. Alongside using ~400 hours of data from mobile manipulators in 100 homes, the dataset includes:
Data from other non-mobile robots
Data from related tasks collected under laboratory conditions
Training examples that require predicting high-level semantic tasks based on robot observation
Verbal language instructions provided to the robot by human supervisors
A variety of multi-modal examples created from web data, such as image captioning, question answering, and object localization
Importantly, the mobile-manipulator-in-home data only represents ~2.4% of their training set. This is a very good indicator that this method can scale: collecting mobile manipulator data from real homes is expensive and has scale constraints. But it turns out that with the right architecture, alternative data forms can significantly reduce the scale of real-world data collection that’s actually needed.
As an aside, you may be wondering if simulation is a data approach they use. I spoke to Lachy about this, and their view is that while simulation is great for locomotion (since you only need to model the robot's dynamics and relatively uniform surfaces), it hasn't been as effective for object manipulation because that requires modeling the physical properties of every object the robot interacts with and the world broadly. Simulation is a part of their strategy, but their greatest focus is real-world data collection and deployment.
After the model is pre-trained, they move to the second stage: fine-tuning the model using a task-relevant subset of the training data alongside verbal instruction demonstrations. Interestingly, the cross-embodiment data is omitted during this step. The overall purpose of this post-training stage is to both specialize the model to a particular use case (e.g., mobile manipulation in a home) and to add an action expert that can output continuous action chunks. These continuous action chunks are made possible via flow matching, a diffusion-inspired method that enables the model to output continuous control trajectories in real time, rather than only predicting discrete action tokens. In other words, these action chunks let the model output smooth, real-time movements instead of step-by-step commands. This makes it better at multi-step tasks like grasping clothing, since the robot's movements are more fluid and less jerky.

Once trained, the model follows a chain-of-thought-style control loop at inference time:
First, it looks at the environment and predicts a natural language subtask. This is just a short description of what action to do next (e.g., “move clothes from the bed”). Then, it generates a 1-second chunk of low-level robot motor actions to execute that subtask.
This loop allows the robot to plan and act iteratively, constantly reassessing the scene and adjusting its behavior as necessary. Because the model breaks long-horizon tasks into smaller semantic goals, it can also handle multi-step activities like cleaning a room or making a bed.
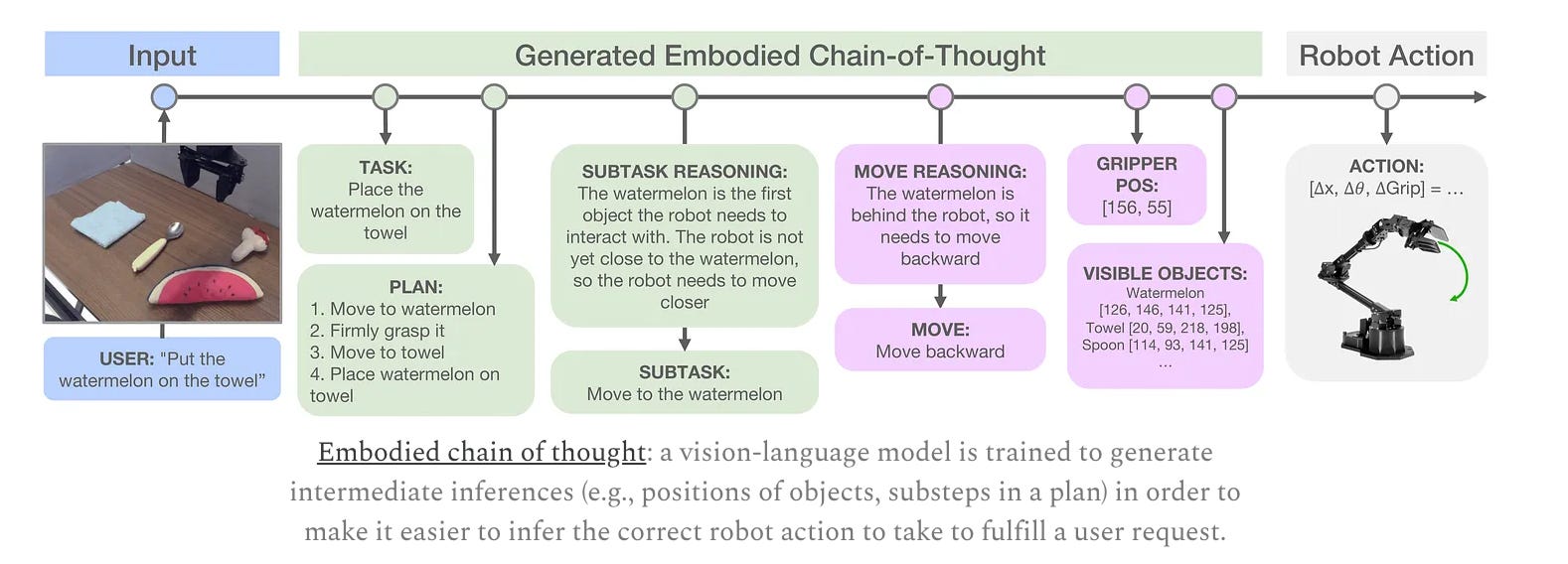
Putting it all together, you have a pre-trained model that is fine-tuned for a specific task and then relies on a chain-of-thought styled approach at inference time:
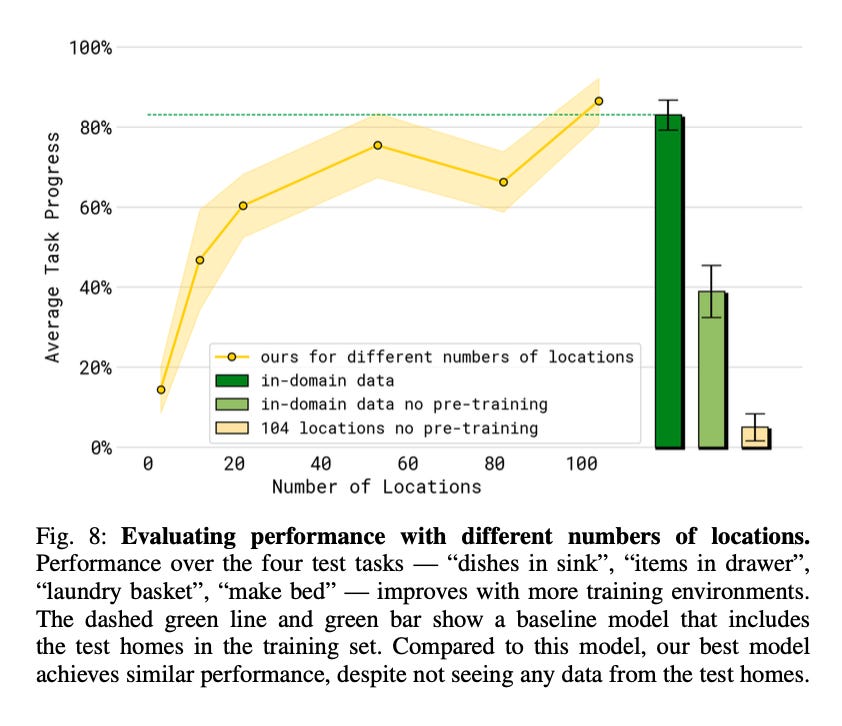
The overall goal of the model is to generalize to new settings and perform multi-stage tasks. In terms of performance, after training on data from 104 homes, the model achieves ~80% average task success on four test tasks (‘dishes in sink’, ‘items in drawer’, ‘laundry basket’, ‘make bed’) in new homes that were never seen during training. Remarkably, this is the same performance that would have been achieved if those homes were included in the training set, showing the power of their co-training approach in reducing the generalization gap.
The model also succeeded at performing a variety of multi-stage tasks when provided with a high-level command (e.g., “place the dishes in the sink”). As discussed above, by using its chain-of-thought approach, the model autonomously determined the most appropriate action to take to execute the broader command, with the majority of commands taking between 2 and 5 minutes. As reported in the paper, the model’s performance with these tasks “goes significantly beyond the results demonstrated with prior vision-language-action models, both in terms of the degree of novelty that the model must handle, and the task duration and complexity”. While the input prompts are relatively simple, the model’s ability to sustain multi-step behaviour over long durations represents an important step forward.

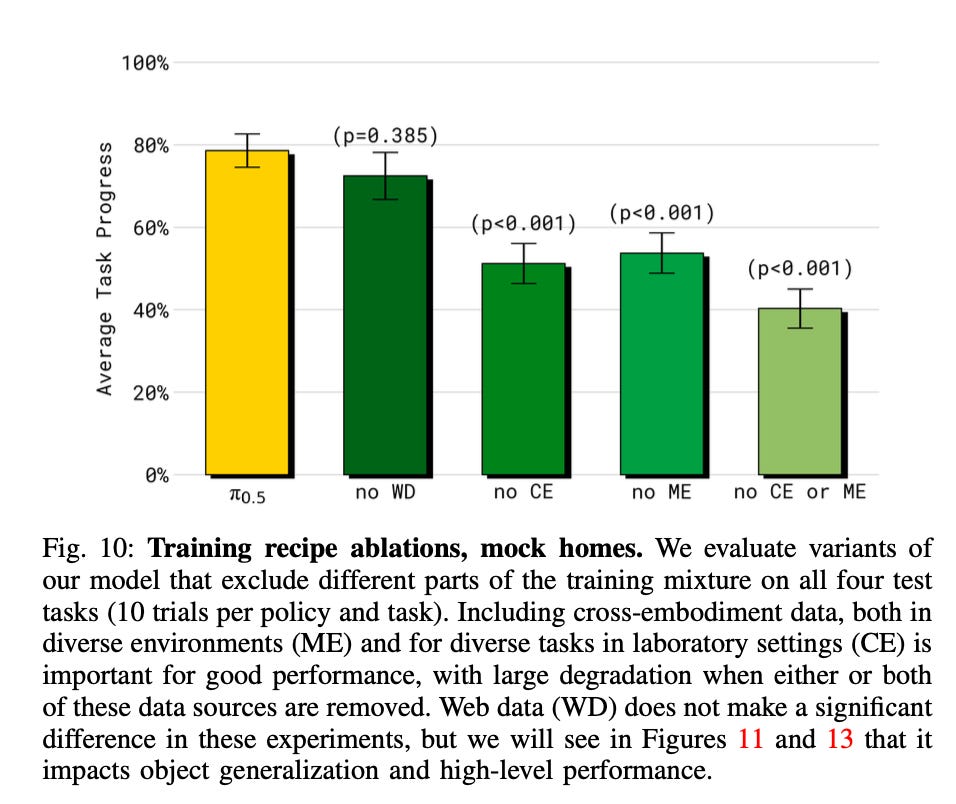
Interestingly, Physical Intelligence also examined how different data sources contributed to the model’s performance. This is especially topical given the conversation regarding the data bottleneck in robotics and whether real-world data at sufficient scale is even attainable. The results were clear: eliminating either the cross-embodiment data collected in controlled lab settings or the data from static manipulators in diverse environments led to a significant drop in performance. As concluded in the paper, “π0.5 benefits considerably from cross-embodiment transfer. Excluding both sources harms performance”.
Looking Ahead
While Physical Intelligence has already produced some remarkable research, the next great unlock lies in driving human-level performance in complex tasks. Some interesting avenues are currently being explored to make that performance jump possible. We’ll hopefully learn more about some of these avenues soon, especially as Karol Hausman hinted at some exciting work on the performance axis just a few weeks ago at the BAAI conference.
Ultimately, we are still searching for research breakthroughs in order to achieve generalized human-level performance at scale. Some of these breakthroughs will come from research on the model side, while the other part will likely come from data. In fact, Physical Intelligence is actively planning to deploy robots to gather more real-world data.
And on top of all this, the big research question still remains unanswered: does an embodied scaling law exist, and if so, on what axis (you can scale across the model, robot fleets, and data types)? My take is that we’ll likely know the answer to that in the near future!
Jobs at Physical Intelligence
If you’re interested in joining the team that’s working to bring general-purpose AI into the physical world, Physical Intelligence is hiring across 10 roles. Check out their jobs here :)
